이글은 Transformer 모델(BERT/GPT 등)의 Library 인 hugging face를 활용한 generator 학습을 위한 글입니다.
모든 내용은 https://huggingface.co/blog/how-to-generate 을 참고하였습니다.
의미 있는 sequence 있는 생성을 위한 학습 중 transformer 모델의 decoder 를 사용 하였으나 repetition 문제를 해결하지 못하여 hugging face 의 generate API를 활용하고자 합니다.
hugging face 의 설치는 pip install transformers 로 완료하였습니다.
블로그의 튜토리얼이 tensorflow 2를 사용하기 때문에 이글에서도 동일한 환경에서 진행합니다.
기본적으로 lanuage generator 모델은 A 라는 단어가 주어졌을때 다음에 나타날 단어의 probability distribution 을 추정하여 새로운 단어를 만들어 나가는 과정입니다.
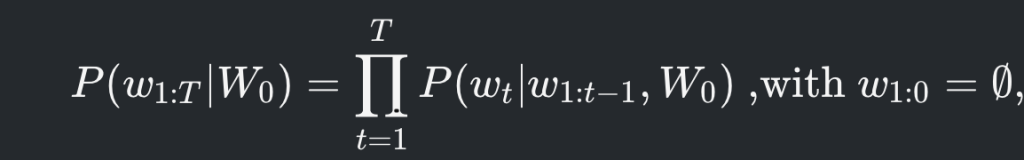
다음 단어의 probability distribution 을 추정하여 문장을 생성하는 모델로는 GPT2, Bart 등이 있습니다.
학습된 distribution 에서 어떤 단어를 선택하는지에 따라 greedy search, beam search, Top-K, Top-p 같은 방법이 존재합니다.
이글에서는 Pre-trained 된 GPT2 모델을 불러와서 단어 선택 방법에 따라 어떤 차이가 있는지 알아보려고 합니다.
-. Greedy Search
단어 A 가 주어졌을때 단순히 probability 가 가장 높은 단어를 선택하는 방법입니다.
가장 간단한 방법이지만 max operator로 인해 전형적인 Maximization bais 에 빠지는 문제가 발생합니다. 문장 generator 에서는 동일 단어가 반복적으로 생성되는 문제가 발생합니다.
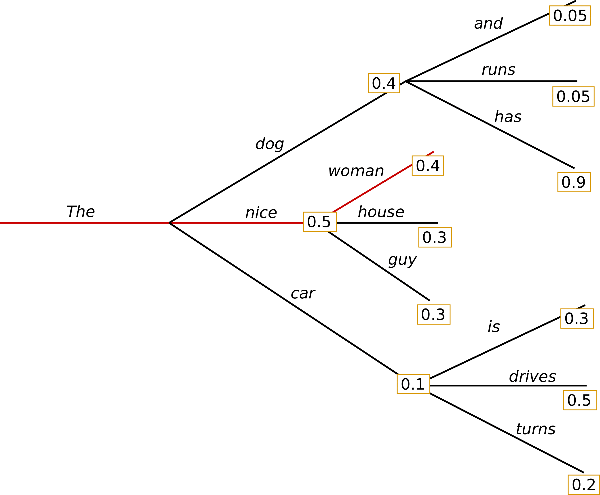
위 그림에서 처럼 The 라는 단어가 주어 졌을때 가장 높은 probability 를 가지는 단어는 nice 입니다. 이럴 경우 The nice woman 이라는 단어만 반복적으로 나타나게 됩니다.
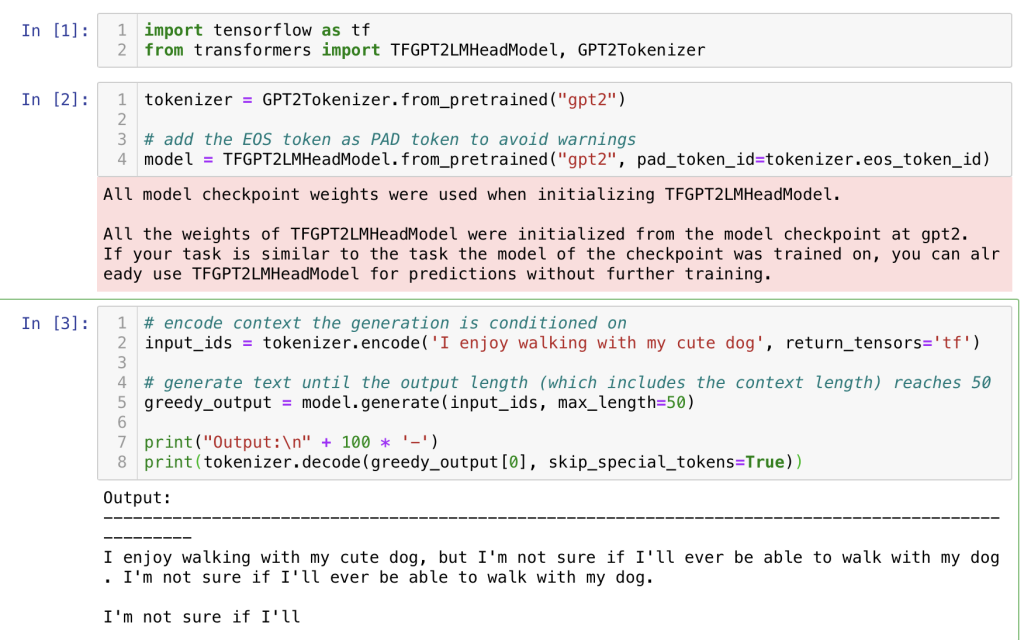
실제 코드를 실행해보면 문장 자체도 어색하지만 (I’ll ever be able to walk with my dog)이 반복적으로 나타나게 됩니다.
-. Beam Search
다시 우리가 보았던 단어 별 probability 그래프를 보면 the 가 주어졌을때 dog 또한 꽤나 높은 probability(0.4) 를 가지고 있습니다. dog 뒤에 나오는 어떤 단어와 조합해볼 수 있다면 nice woman 보다 높은 probaility 를 가진 문장을 만들 수도 있을지 모릅니다.
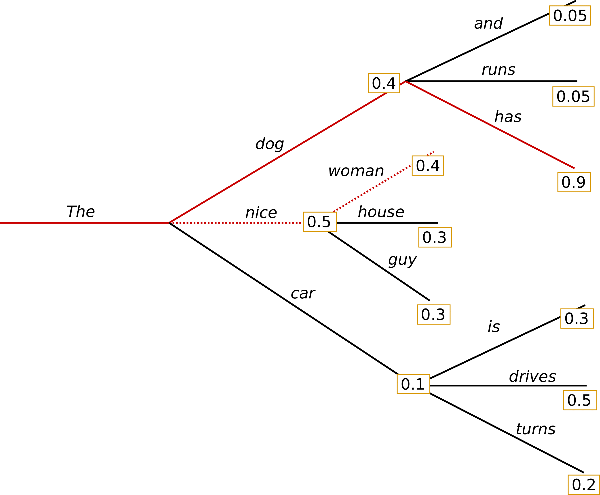
그래서 단순히 The 이후의 하나의 단어만 보는게 아닌 beam size 만큼의 단어를 확인해봅니다. 이 경우 dog has 는 0.4 * 0.9 = 0.36 이고 nice woman 은 0.5 * 0.4 = 0.2 입니다. the dog has 라는 시퀀스가 좀 더 높은 probability 를 가지게 되어 선택됩니다.
greedy 보다는 exploration 관점에서 beam size 만큼 좀 더 많은 단어를 탐색 할 수 있지만 그럼에도 max probability 를 선택 하기 때문에 Maximization bais 에서 자유로울 수 없는 방법입니다. (반복이 나타날 수 있다는 이야기)
hugging face 에서는 num_beams 옵션으로 사용 가능합니다.
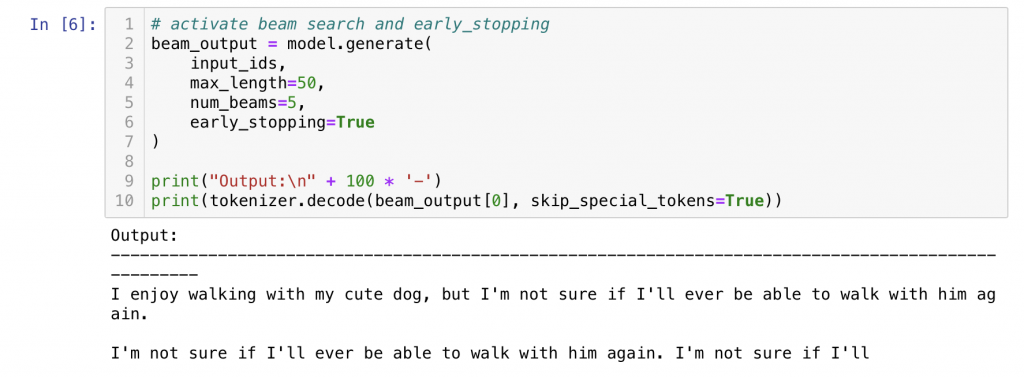
아쉽지만 실제로도 동일 문장이 반복적으로 나타나고 있습니다.
Beam Search 를 사용하면서도 반복을 해결 하기 위한 방법으로 repeat-n-gram을 제한하는 방법이 있습니다. 코드의 ouput 에서 walk with him 이라는 3-gram 이 반복적으로 나타나기 때문에 제한 한다면 반복이 줄어든 좀더 좋은 문장을 생성할 수 있을것 입니다.
하지만, Beam Search 가 가진 max operator 의 한계는 여전히 존재합니다. New York 에 관한 글을 쓴다면 지명은 반복적으로 나와야하는데 repeat를 제한해서 또다른 어색한 문장이 생성 될 수 있습니다.
결국 randomess 를 잘 control 해서 distribution 에서 적절한 샘플을 뽑아내는게 가장 중요할 것입니다.(Sampling)
-. Sampling
다음 단어가 나올 어떤 probability distribution 에서 random하게 단어를 선택합니다.
Randomess 를 통해 Maximization bais 문제가 해결 될것으로 기대 됩니다(단어 반복 해결)
HugginFace 에서는 generate 함수에 do_sample=True 로 samplinig 을 사용할 수 있습니다.
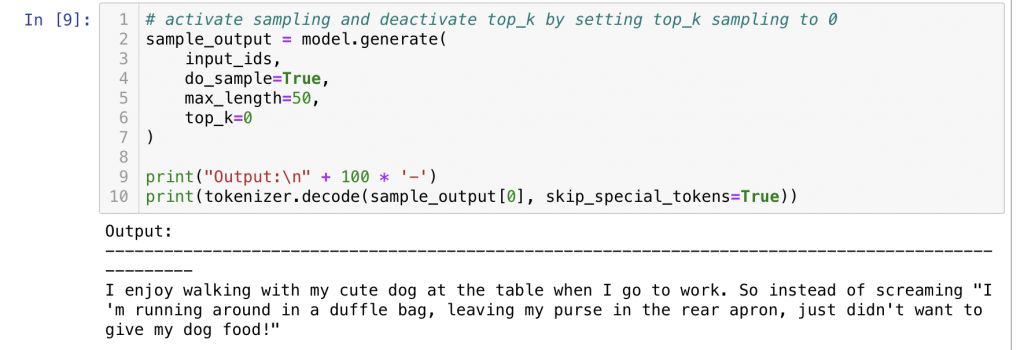
Sampling 방법을 사용해보니 단어 반복은 사라졌지만 문장이 의미가 없고 어색한것 같습니다.
softmax 함수의 temperature 를 적용 하여 높은 probability 를 가진 단어가 좀더 선택되도록 할 수 있지만 randomess 로 인한 어색한 단어 조합은 쉽게 해결되지 않을것 같습니다.
GPT2 는 이런 문제를 해결 하기 위해 Top-K / Top-p 방법을 도입했습니다.
-. Top-K
sampling 시 probability 가 높은 k 번째 단어 중 sampling 하는 방법 입니다. 자주 등장 하지 않는 단어를 sampling 에서 제외하여 좀 더 자연스러운 문장 생성을 기대할 수 있습니다.
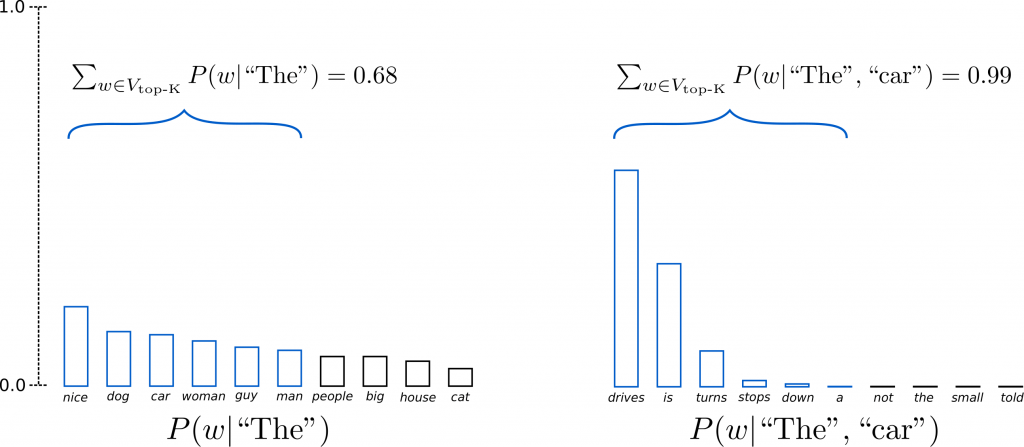
The 가 주어 졌을때 top 6 중 sampling 하고 The car 에 대해 서도 top 6 로 sampling 합니다. The car 에 대해서는 high probability 로 drives 가 선택되어 좀 더 자연 스러운 문장을 기대할 수 있을것 같습니다.
hugging face 에서는 top_k 라는 파라로 Top-K 방법을 사용할 수 있습니다.
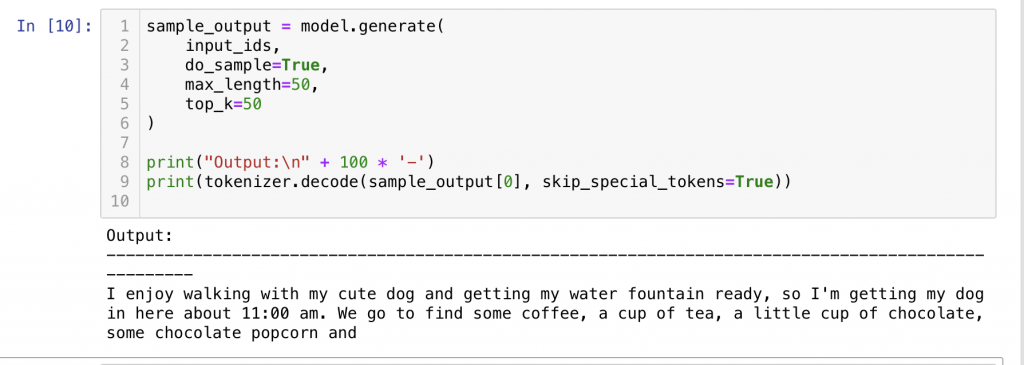
Vanilla Sampling 보다는 좀더 자연스러워 보이지만 아직 어색한 부분이 많이 보입니다.
-. Top-p
Top-p 방법은 k 같이 단어 수로 sampling 대상을 선정하는것이 아닌 probability 합산으로 sampling 대상을 선택합니다. 만약 p가 0.9 일 경우 top 에서 부터 합산 probability 가 0.9 가 되는 순간 까지 sampling 대상을 선정합니다.
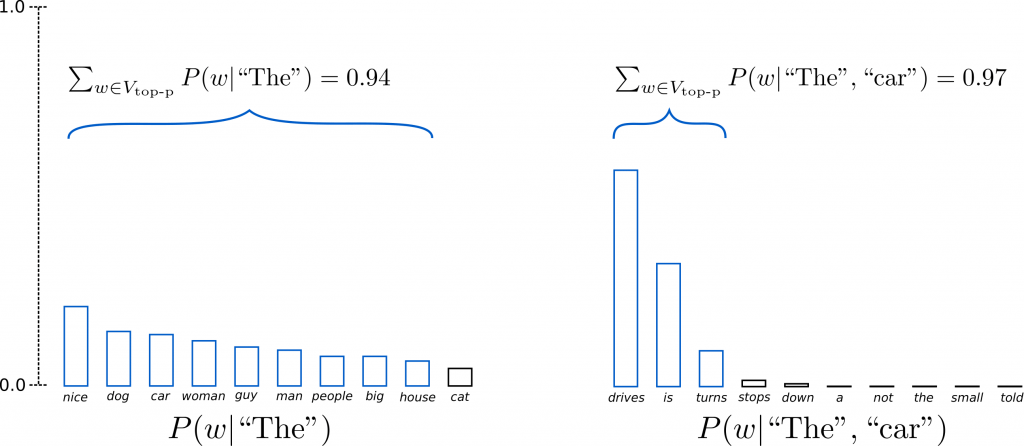
The car 가 주어졌을때 top-k 방법(k=6)은 down , a 같은 어색한 단어를 선택할 가능성이 있지만 top-p는 probability 가 높은 drives/is/turns 중 sampling 하여 좀 더 자연스러운 문장이 완성될것이라고 기대할 수 있습니다. 또한 왼쪽처럼 distribution이 flat 할 경우 좀더 많은 단어의 exploration이 가능하고 오른쪽처럼 distribution이 sharp 할 경우 정확한 단어를 선택할 확률이 높아지는 장점을 가질 수 있습니다.
hugging face 에서는 top_p 라는 옵션으로 top-p 방법을 사용 할 수 있습니다.
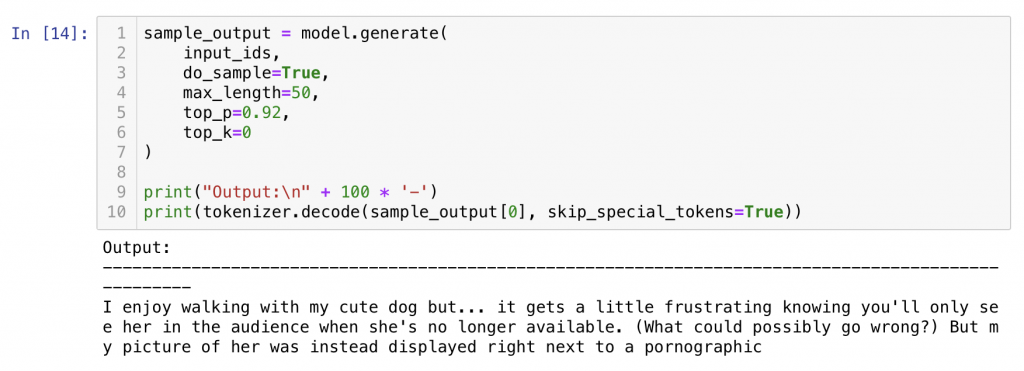
생성된 문장이 완전 자연스러워 보이지는 않지만 그럼에도 greedy 방법과 비교해서 많은 발전이 있었습니다.
https://huggingface.co/blog/how-to-generate 에서 소개한 간단한 문장 생성 예제를 따라가면서 단어 선택 방법별 특징을 확인해 보았습니다.
튜토리얼의 결론에서 저자는 case 별로 각 선택 방법을 적용시켜보며 최적의 방법을 찾으라고 조언합니다. 문장 생성 모델은 여전히 빠르게 발전하고 있고 다양한 시도가 진행되고 있어 앞으로 다른 다양한 방법이 등장할 것 같습니다.