LOL 게임 데이터를 바탕으로 RNN을 이용해 18레벨까지의 skill 시퀀스를 만들어보는 작업을 하고 있습니다.
이 toy 과제의 목적은 학습된 모델이 생성하는 시퀀스가 게임의 규칙을 이해한 skill 시퀀스 생성 입니다. 데이터만으로 생성된 skill 시퀀스는 6번째에 R이 나와야하고 QWE 스킬은 5번까지만 반복되어야하는 규칙을 찾아야합니다.
RNN(LSTM)으로 학습을 진행했지만 window size, 데이터 구성 등의 이유에서 원하는 결과를 얻지 못했습니다.
seq2seq 학습에서 최근 트랜드는 RNN보다는 데이터가 time 별로 얼마나 영향을 받았는지를 나타내는 Attention 을 활용한 모델들이 사용되고 있습니다. 2017년 발표된 Attention Is All You Need 라는 논문 이후 attension 을 이용한 seq2seq 모델들이 많이 나오고 있는데요.
그 중 Transformer 모델을 이용하여 학습해보겠습니다.
( 기계 번역을 위한 Transformer 모델은 Tensorflow 블로그에 자세히 설명되어 있습니다.)
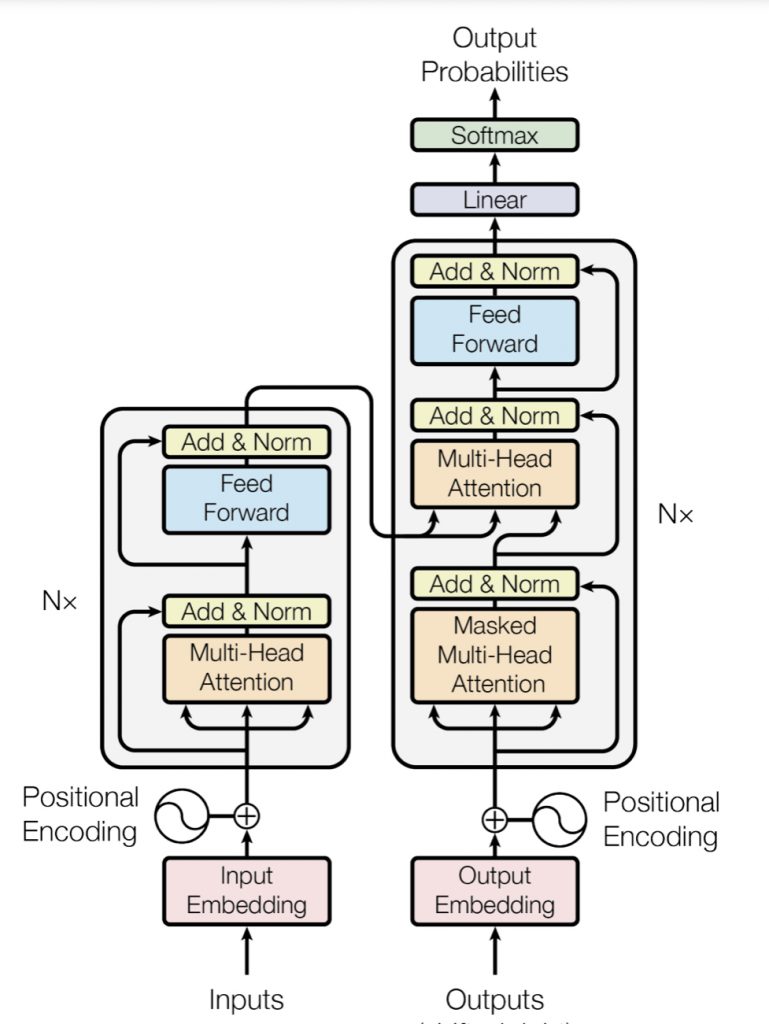
Transformer 모델은 크게 Encoder와 Decoder로 구성됩니다. 각각의 모델은 정확히 위의 이미지와 같은 layer를 가지고 있고 RNN cell이 아닌 attention을 계산하는 layer와 FC 레이어 만으로 seq2seq를 학습합니다.
Transformer 모델에 대한 자세한 내용은 Tensorflow 블로그 에서 확인가능합니다.
(RNN과 LSTM 그리고 Attention 모델에 대한 사전 이해가 어느 정도 있어야 따라 갈 수 있습니다.)
다시 LOL skill 학습 모델로 돌아가겠습니다.
기본적인 구성은 기계학습 코드와 비슷하게 구성하였습니다. Transformer의 장점중 하나는 RNN 처럼 window 사이즈를 정하지 않아도 된다는 점입니다. Transformer 모델에서는 각 time 별(LOL 데이터에서는 level별) attention을 계산합니다.
최종 목적은 Sequence Generator 이기 때문에 y에 input과 동일한 x 값을 주어 encoder/decoder를 학습 시킨 후 decoder만을 활용하여 시퀀스를 생성할 것입니다.
(Auto Encoder 모델과 비슷한 원리로 동작)
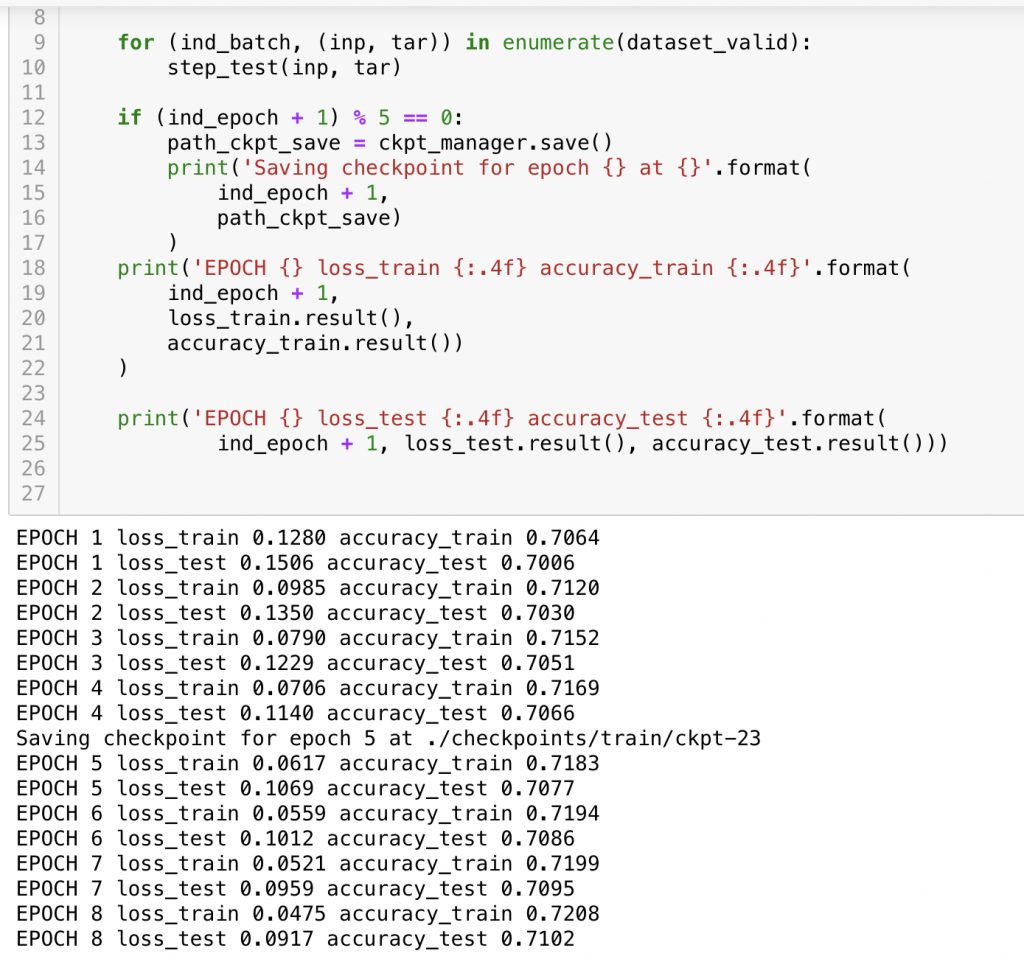
학습 결과 Loss는 빠르게 떨어지고 있습니다. 하지만 Acurracy가 원하는 만큼 떨어지지 않습니다. Batch Layer나 Drop out 을 통해 over-fitting을 개선하고 hyper para tunning 을 진행해야할것 같습니다.
아직 충분히 학습 되지 않았고 decoder만 분리하지 않았지만 seq를 생성 해보았습니다.
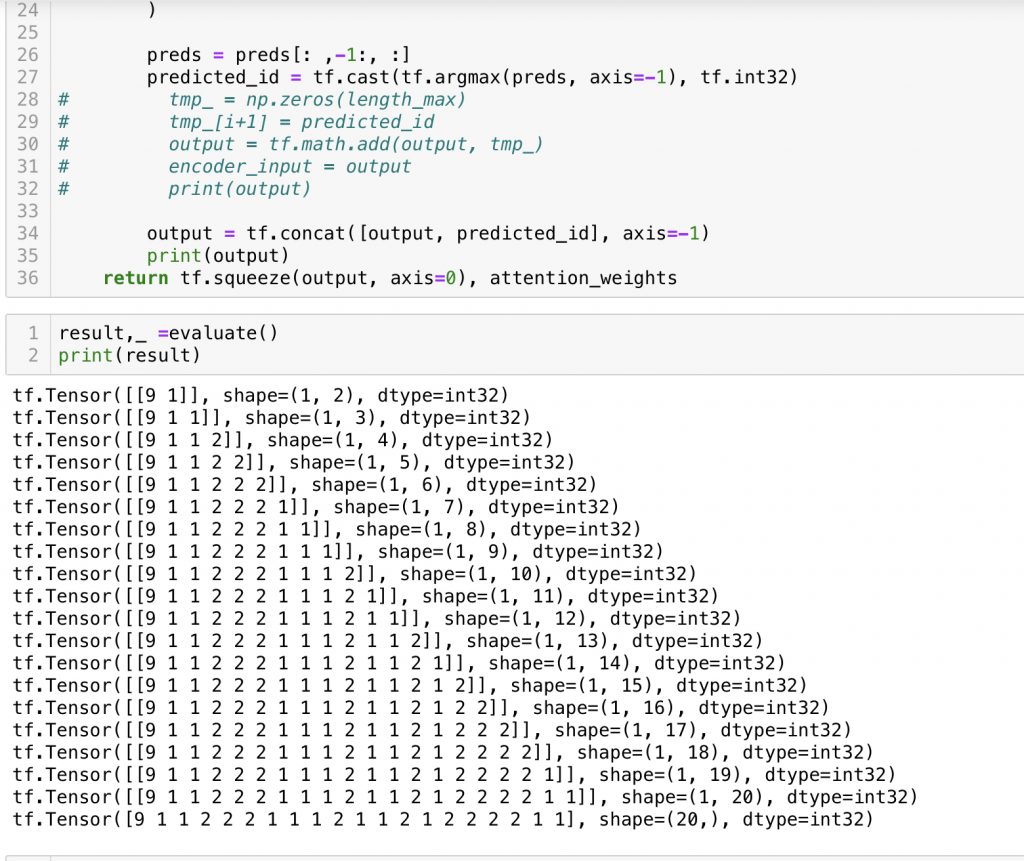
기대했던 seq가 아닙니다.
hyper para tuning 과 decoder분리 이후 다시 시퀀스를 생성해보겠습니다.
2020.08.18 추가
이글에서 사용한 greedy selection을 이용한 generator는 반복적인 문장을 가지는게 common 한 문제라고 합니다.(다음 단어 선택시 np.argmax 로 prediction)
transformer를 직접 구현하는것 보다는 잘 만들어진 API 를 활용하는게 훨씬 좋은 방법일것 같습니다.
https://huggingface.co/blog/how-to-generate 글에서 소개하는 beam search/Top-K/Top-p 같은 방법을 활용한 generator를 만들어 볼 예정입니다.
(huggingface library 사용)