[M/L]LOL 데이터를 활용한 Skill 트리 학습(2) 에 이어 진행합니다.
기존의 N-gram 형태의 rnn 으로는 원하는 결과가 나오지 않아 Tensorflow 공식 홈페이지의 RNN Tutorial를 참고해서 진행해보았습니다.
https://www.tensorflow.org/tutorials/text/text_generation?hl=ko
(한글로 된 tensorflow 공식 tutorial 페이지)
먼저 데이터 셋을 tutorial처럼 하나의 text 뭉치처럼 만들기 위해 join 합니다.
|
1 2 3 4 5 |
new_data = [] for data in lol_data: new_data.append(''.join([idx2char[int(x)] for x in str(data)])) # print(lol_data[0]) stringfy_data = '\n'.join(new_data) |
그리고 window size가 6인 dataset 을 구성해줍니다.
|
1 2 3 4 5 6 7 8 |
sequences = char_dataset.batch(seq_length+1, drop_remainder=True) def split_input_target(chunk): input_text = chunk[:-1] target_text = chunk[1:] return input_text, target_text dataset = sequences.map(split_input_target) |
이후 정확히 tutorial과 동일한 RNN 모델을 생성 합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 문자로 된 어휘 사전의 크기 vocab_size = len(set(stringfy_data)) # 임베딩 차원 embedding_dim = 256 # RNN 유닛(unit) 개수 rnn_units = 1024 def build_model(vocab_size, embedding_dim, rnn_units, batch_size): model = tf.keras.Sequential([ tf.keras.layers.Embedding(vocab_size, embedding_dim, batch_input_shape=[batch_size, None]), tf.keras.layers.LSTM(rnn_units, return_sequences=True, stateful=True, recurrent_initializer='glorot_uniform'), tf.keras.layers.Dense(vocab_size) ]) return model |
input shape이 6 이고 1024의 layer가 옆으로 늘어진 RNN 모델을 생성했습니다.
(Embedding 모델에 대해서는 추가 학습이 필요)

200 epochs로 모델을 실행해보았지만 loss가 떨어지지 않습니다.
모델이 잘못되었거나 입력 데이터가 잘못된것 같습니다.
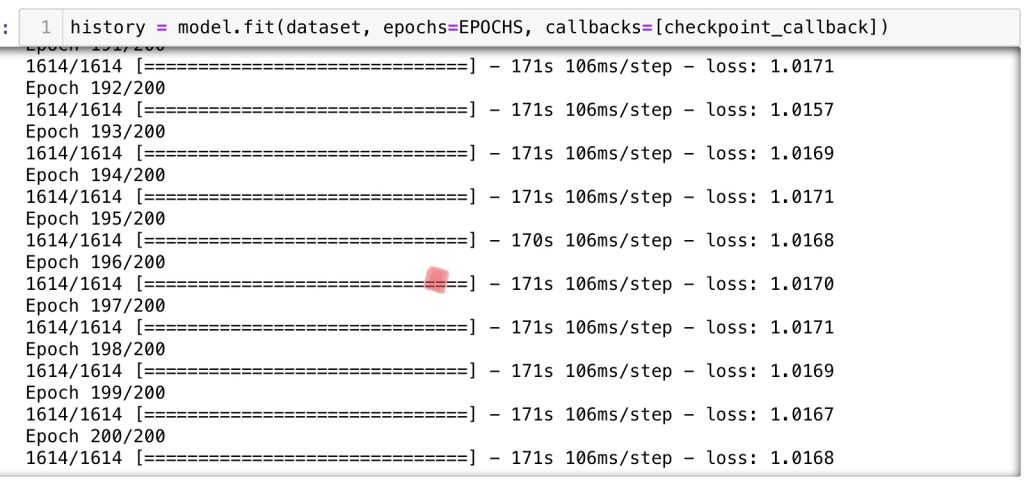
18개의 seq를 만들어 보았지만 역시 기대했던 결과와 전혀 다릅니다.
(Q는 5개만 나와야하고 R는 6번쨰 나와야하는 등의 규칙이 전혀 지켜지지 않음)

기본 RNN이 아닌 Stacked RNN 혹은 Dynamic RNN 모델을 적용하고
입력 데이터 또한 게임별 구분을 명확히 할 수 있는 방법에 대한 추가 고민이 필요할것 같습니다.