[M/L]LOL 데이터를 활용한 Skill 트리 학습(1)에 이어 진행합니다.
수집된 데이터 set 은 아래와 같습니다.
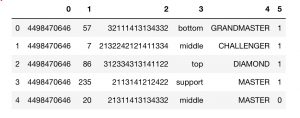
2번째 column의 데이터가 프로게이머들이 선택한 skill sequence 입니다.
경기에 따라 18 레벨 전에 끝날수도 있기 때문에 꼭 18개의 sequence 가 존재하는건 아닙니다.
문장을 bi-gram으로 나누듯이 skill sequence를 학습 가능한 형태의 n-gram으로 만들어보겠습니다.
skill set의 n-gram은 { 1,2,3,4 }의 set으로 구성된 n = 19 인 데이터 set 입니다.
|
1 2 3 4 5 6 7 |
sequences = list() for line in data: line = str(line) for i,a in enumerate(line): sequence = [c for c in line[:i+1]] sequence.insert(0,'6') #begin point를 6으로 설정 sequences.append(sequence) |
그리고 max length = 19 보다 짧은 데이터에 대해서는 0으로 padding 해줍니다.
|
1 |
sequences = pad_sequences(sequences, maxlen=max_len, padding='pre') |
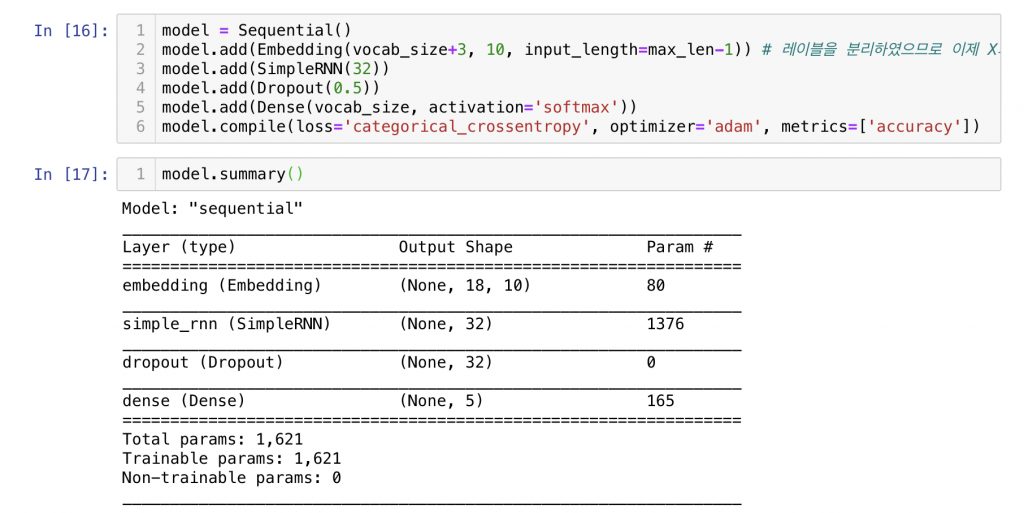
마지막으로 가장 기본적인 RNN 모델을 생성하여 학습시켜 보겠습니다.
결과가 좋지 않네요
validation loss 가 줄어들지 않습니다.
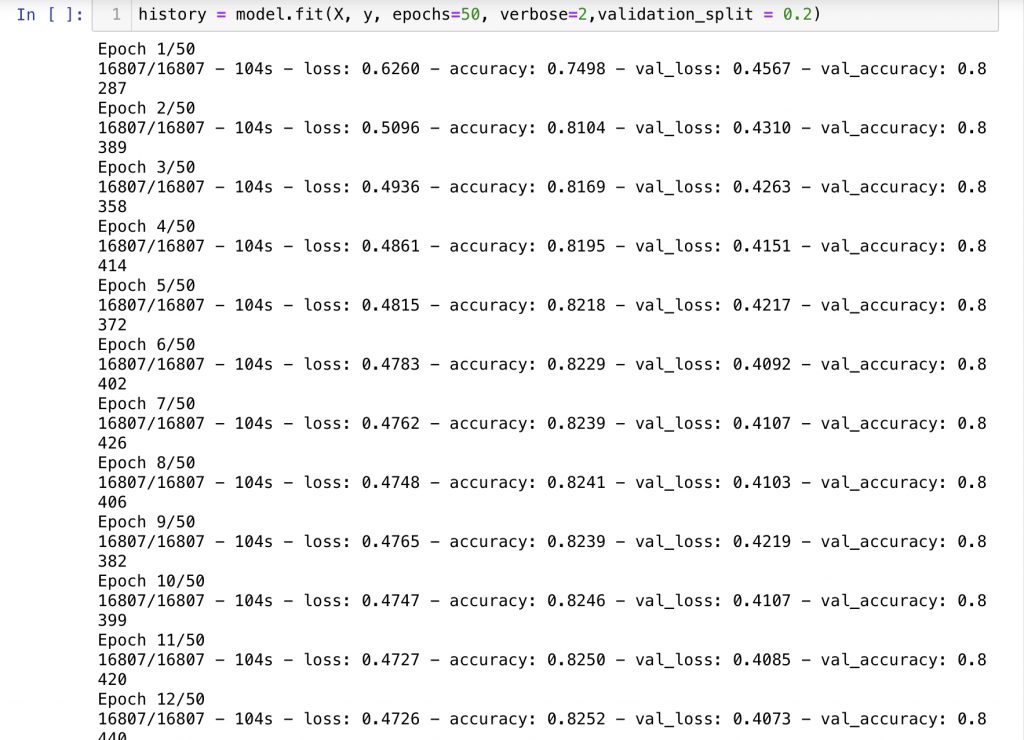
모델을 다시 구성하고 hyper paramerter들을 튜닝해보겠습니다.